Official websites use .gov
A .gov website belongs to an official government organization in the United States.
Secure .gov websites use HTTPS
A lock (
) or https:// means you’ve safely connected to the .gov website. Share sensitive information only on official, secure websites.
LRE11 Results
The 2011 NIST Language Recognition Evaluation Results
Date of Release: Tuesday, January 10, 2013
The 2011 NIST Language Recognition Evaluation (LRE11) was the fifth in the evaluation series that began in 1996 to evaluate human-language recognition technology. NIST conducts these evaluations in order to support language recognition (LR) research and help advance the state-of-the-art in language recognition. These evaluations provide an important contribution to the direction of research efforts and the calibration of technical capabilities. The evaluation was administered as outlined in the official LRE11 evaluation plan. More information is available in a brief presentation.
Disclaimer
These results are not to be construed, or represented as endorsements of any participant's system or commercial product, or as official findings on the part of NIST or the U.S. Government. Note that the results submitted by developers of commercial LR products were generally from research systems, not commercially available products. Since LRE11 was an evaluation of research algorithms, the LRE11 test design required local implementation by each participant. As such, participants were only required to submit their system output to NIST for uniform scoring and analysis. The systems themselves were not independently evaluated by NIST.
The data, protocols, and metrics employed in this evaluation were chosen to support LR research and should not be construed as indicating how well these systems would perform in applications. While changes in the data domain, or changes in the amount of data used to build a system, can greatly influence system performance, changing the task protocols could indicate different performance strengths and weaknesses for these same systems.
Because of the above reasons, this should not be interpreted as a product testing exercise and the results should not be used to make conclusions regarding which commercial products are best for a particular application.
Evaluation Task
The 2011 NIST language recognition evaluation task was language detection in the context of a fixed pair of languages: Given a segment of speech and a specified language pair (i.e., two of the possible target languages of interest), the task was to decide which of these two languages is in fact spoken in the given segment, based on an automated analysis of the data contained in the segment.
Evaluation Languages
There were 24 target languages included in LRE11. Table 1 lists the included target languages.
Table 1: The 24 target languages.
Target
LanguagesArabic Iraqi Arabic Levantine Arabic Maghrebi Arabic MSA Bengali Czech Dari English (American) English (Indian) Farsi/Persian Hindi Lao Mandarin Panjabi Pashto Polish Russian Slovak Spanish Tamil Thai Turkish Ukranian Urdu
Training Data
Participants in the evaluation were given conversational telephone speech data from past LREs to train their systems and narrowband broadcast data from multiple broadcast sources.
Evaluation Data
The evaluation data contained narrowband broadcast speech from multiple broadcast sources. All evaluation data was provided in 16-bit 8 KHz format. Table 2 shows the language statistics. Some languages have more data than others due to data availability. Participants could also augment this data with additional data obtained independently. However, any additional data that sites utilized must be publicly available and the source for the data had to be documented in their system descriptions.
Table 2: Counts of telephone segments, broadcast segments, and broadcast sources per language.
Lang.
Number of Telephone Segments
Number of Broadcast Segments
Number of Broadcast Sources
Arabic Iraqi
1224
0
0
Arabic Levantine
1224
0
0
Arabic Maghrebi
1215
0
0
Arabic MSA
0
1218
49
Bengali
660
681
19
Czech
537
837
4
Dari
858
1647
27
English-Am.
363
993
8
English-Ind.
150
1098
45
Farsi
591
624
21
Hindi
210
1047
32
Lao
379
379
5
Mandarin
777
519
9
Panjabi
1191
33
5
Pashto
465
771
12
Polish
726
717
1
Russian
417
906
4
Slovak
516
726
3
Spanish
693
564
16
Tamil
600
642
9
Thai
195
1014
5
Turkish
501
915
9
Ukranian
357
201
4
Urdu
672
771
7
Test Segments
Each of the target languages included 100 or more test segments of each of the three test durations. All segments were in 16-bit linear pcm format, and segments derived from conversational telephone speech were not distinguished from segments derived from narrow band speech.
Evaluation Rules
Participants were given a set of rules to follow during the evaluation. The rules were created to ensure the quality of the evaluation and can be found in the evaluation plan.
Performance Measurement
Performance was measured for each target language pair. For each pair L1/L2, the miss probabilities for L1 and for L2 over all segments in either language were determined. In addition, these probabilities were combined into a single number representing the cost performance of a system for distinguishing the two languages (see Figure 1). An overall performance measure for each system was computed as an average cost for those target language pairs presenting the greatest challenge to the system.
Let N be the number of target languages included in the evaluation. For each segment duration (30-second, 10-second, or 3-second), a system's overall performance measure was based on the N target language pairs for which the minimum cost operating points for 30-second segments are greatest. For each segment duration, the performance measure was then the mean of the actual decision operating point cost function values over these N pairs.
Thus calibration errors were not considered in choosing which N cost function pairs to average, but did contribute to the system's overall performance measure.
Figure 1: Evaluation metric measuring system performance for a language pair. CL1, CL2 and PL1 are application model parameters, which may be viewed as the costs of a miss for L1 and L2, respectively, and PL1 as the prior probability for L1 with respect to this language pair
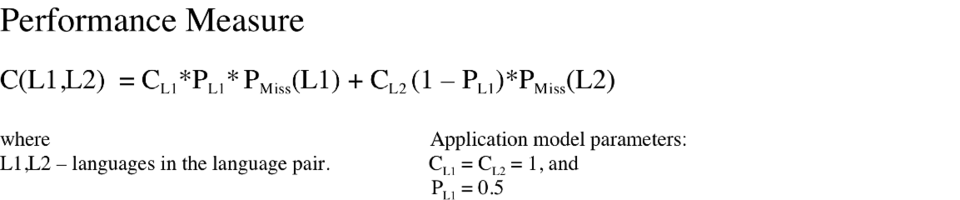
Participating Organizations
A diverse group of organizations from three continents participated in the evaluation. Table 3 lists these organizations.
Table 3: Participating organizations in LRE11.
Location Universidad Autonoma de Madrid
Madrid, Spain
L2F-Spoken Language Systems Lab INESC-ID Lisboa
Lisbon, Portugal
University of the Basque Country
Brno, Czech Republic
Brno University of Technology
Brno, Czech Republic
Chulalongkorn University
Bangkok, Thailand
University of Texas at Dallas
Richardson, Texas, USA
University of the Basque Country#13;
Bizkaia, Spain
University of Zaragoza
Zaragoza, Spain
Chinese Academy of Sciences
Beijing, China
iFlyTek Speech Lab, EEIS University of Science and Technology of China
HeFei, AnHui, China
Institute for Infocomm Research
Fusionpolis, Singapore
Indian Institute of Technology, Kharagpur
Kharagpur, India
Spoken Language Systems Lab INESC-ID Lisboa
Lisbon, Portugal
LABRI-Universitee Bordeaux
Talence, France
CNRS-LIMSI (Laboratoire d'Informatique pour la Mécanique et les Sciences de l'Ingénieur)
Orsay, France
Laboratorie Informatique D'Avignon
Avignon, France
MIT Lincoln Laboratory
Lexington, MA, USA
MIT Computer Science and Artificial Intelligence Laboratory
Cambridge, MA, USA
National Taipei University of Technology
Taipei, Taiwan
Tsinghua University Department of Electrical Engineering
Beijing, China
Ultra-Electronics Audisoft
Cirencester, United Kingdom
Swansea University
Swansea, United Kingdom
Evaluation Results
The results are presented without attribution to the participating organizations in accordance with a policy established for NIST Language Recognition Evaluations.
What follows are the overall scores for primary systems in LRE11 (Figure 2), the language pairs most often contributing to the overall scores for top primary systems (Figure 3), and a language confusability matrix for a leading primary system (Figure 4).
Overall Scores
Figure 2: The overall performance measure for the primary systems in LRE11. Each of the 17 stacked-bars represents the performance for one primary system. The royal blue bars show performance on 30-second segments, the royal blue and cyan bars combined show performance on 10-second segments, and the royal blue, cyan, and white bars combined show performance on 3-second segments.
Language Pairs Contributing to Overall Scores
Figure 3: The language pairs most often contributing to the overall primary measure of the leading six primary systems.
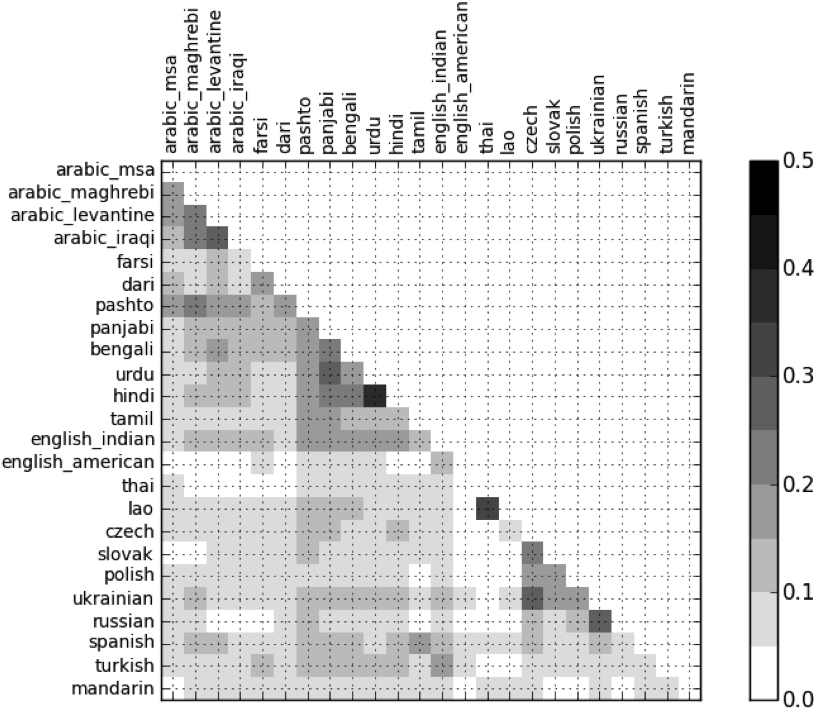
Language Pair Confusability Matrix
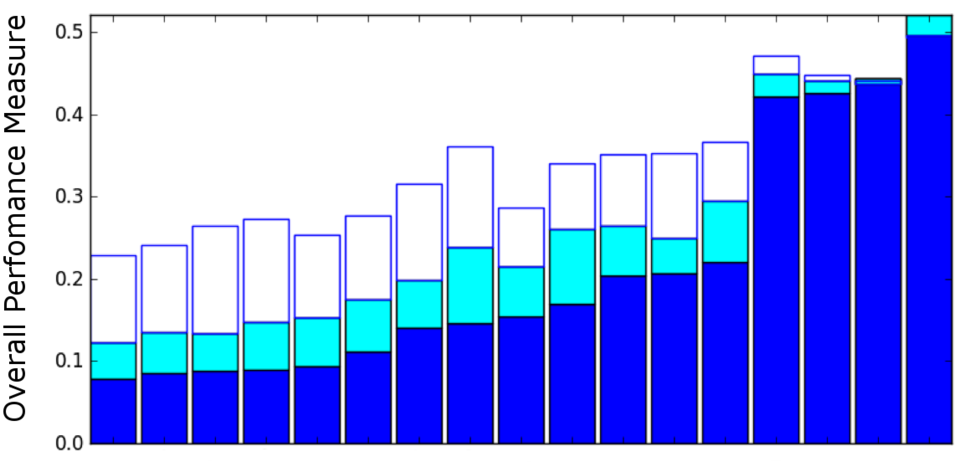
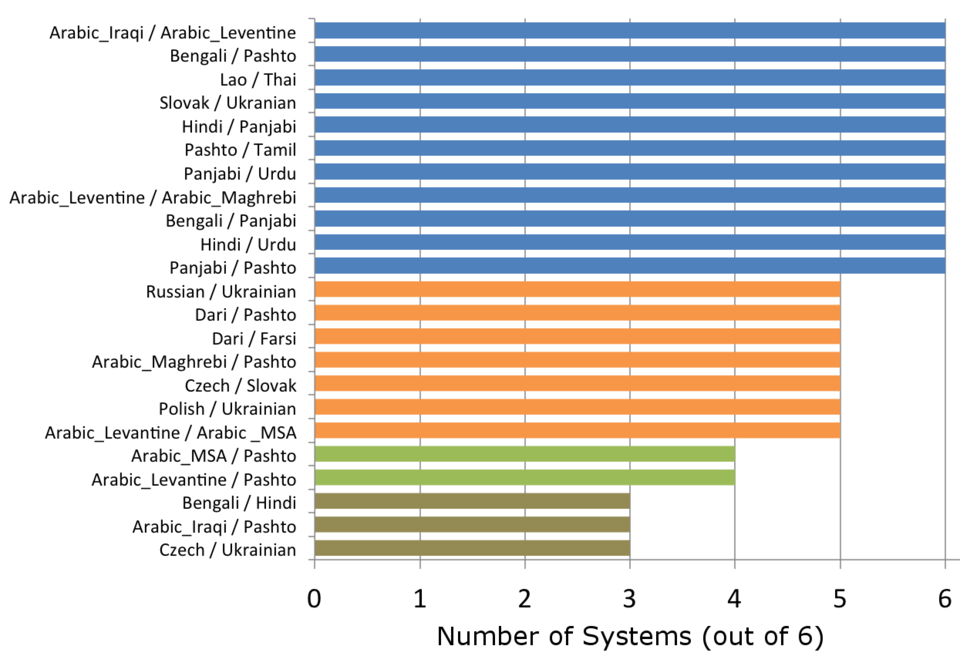
Figure 4: The language confusability matrix for a leading system on 3 second segments. The darker the cell for a language pair, the higher the cost the system had for that pair.